Аварии ЦОД и их профилактика: новости от AeroData, Sabre Corp, Facebook, Wells Fargo, CenturyLink и не только
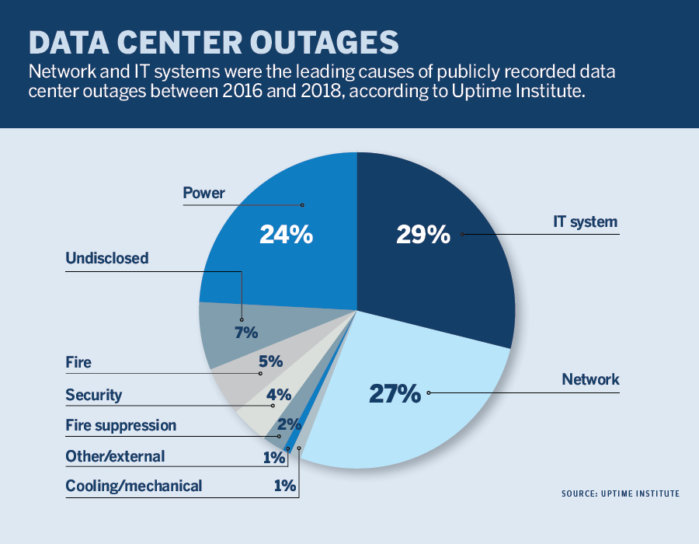 Поскольку корпоративные вычислительные среды постоянно усложняются, сбои в работе IT-систем и сетевые ошибки становятся причиной растущего числа аварий в центрах обработки данных, вызывая все больше незапланированных простоев.
Поскольку корпоративные вычислительные среды постоянно усложняются, сбои в работе IT-систем и сетевые ошибки становятся причиной растущего числа аварий в центрах обработки данных, вызывая все больше незапланированных простоев.
Чтобы оценить тренды в этой сфере, организация Uptime Institute проанализировала информацию о 163 даунтаймах ЦОД за последние три года, о которых сообщалось в традиционных СМИ или в социальных сетях. Количество доступных данных в течение охваченного исследованием периода постоянно росло. Исследователи собрали данные о 27 авариях в 2016 году, о 57 — в 2018 году и о 78 — в 2018 году.
Один из ключевых выводов исследования Uptime Institute сводится к следующему: проблемы в работе силовой инфраструктуры все реже становятся причинами сбоев в работе ЦОД, тогда как проблемы с сетевой инфраструктурой и ИТ-системами, напротив, все чаще выступают причинами аварий. Это подтверждают свежие данные об авариях в ЦОД, случившихся за последние месяцы.
Сбой в ЦОД CenturyLink мешал американцам связываться с операторами служб неотложной помощи
В ночь на 27 декабря 2018 года центр обработки данных американской телекоммуникационной компании CenturyLink в Брумфилде, штат Колорадо (США), ушел в офлайн, из-за чего многие американцы в Вашингтоне и других штатах лишились возможности дозвониться до операторов служб неотложной помощи.
Последовавшее за этим инцидентом расследование показало, что даунтайм ЦОД, продолжавшийся почти два дня, был вызван неисправной сетевой картой. Карта начала «передавать недопустимые пакеты на устройства», что вызвало проблемы, которые заставили компанию перезагрузить большую часть сетевого оборудования в одном из своих ЦОД.
По стандартам современных поставщиков телекоммуникационных и облачных услуг, двухдневное отключение — это вечность. Не совсем понятно, как выход из строя всего лишь одного элемента оборудования может вызвать отказ такого масштаба, учитывая уровни резервирования, которые провайдеры телекоммуникационных услуг закладывают при проектировании и развертывании своих систем.
Система правосудия в Великобритании замерла из-за проблем в ЦОД
Система правосудия в Великобритании оказалась «на лопатках» из-за перебоев в работе сетевой инфраструктуры ЦОД, функционирующего при поддержке компаний Atos и Microsoft. Крупный сбой, затронул вычислительную инфраструктуру британского Министерства юстиции и привел к выходу из строя внутренней электронной почты системы уголовного правосудия, системы регистрации информации в ходе судебных заседаний и ряда других критически важных платформ.
Эксперты называют сокращение бюджетного финансирования Министерства юстиции на 40 процентов в качестве одной из причин даунтайма. Также следует отметить, что британское правительство ранее запустило программу реформирования судов стоимостью в 1,2 миллиарда фунтов стерлингов, в результате которой сотни судов были закрыты, тысячи сотрудников судов –сокращены, при этом была поставлена задача перевести в цифровой формат многие судебные процессы.
Из-за перебоев в работе ЦОД Facebook в офлайн ушли Instagram, WhatsApp и сайт соцсети
В прошлом месяце соцсеть Facebook пережила одно из самых длительных отключений в своей истории. Причина перебоев, которые длились около 14 часов, остается неизвестной. Сбой затронул не только сайт Facebook, но и такие популярные сервисы как Instagram, WhatsApp и Messenger.
Проблемы начались 13 марта около 9 утра по тихоокеанскому времени и продолжали мешать работе сервисов американской компании до обеда 14 марта. По мнению экспертов, причина кроется в прикладном программном обеспечении или сетевой инфраструктуре. Одни источники сообщают, что всему виной перегрузка базы данных, другие указывают на проблемы с маршрутизатором.
Два года назад руководство Facebook объявило, что переносит данные приобретенного сервиса WhatsApp из облака IBM в свои собственные центры обработки данных. Тот факт, что пользователи WhatsApp столкнулись с перебоями в работе сервиса во время глобального даунтайма Facebook, может свидетельствовать об успешном завершении данного проекта.
Чтобы свести к минимуму вероятность сбоев в ЦОД, руководство Facebook ранее создало команду Project Storm, которая проводит стресс-тестирование центров обработки данных с применением различных тестов, включая полное отключение электроснабжения дата-центра из центральной сети.
Перебои в работе ЦОД AeroData заставили американских авиаперевозчиков задержать рейсы
Перебои в работе программного обеспечения для планирования авиаперелетов в дата-центре AeroData привели к задержке почти 3 тысяч авиарейсов в США. Инцидент длился 40 минут и произошел утром в понедельник 1 апреля. В число затронутых авиакомпаний входят Delta, United, United Continental, JetBlue, Southwest, SkyWest и Alaska. На юго-западе США было зафиксировано наибольшее число задержек авиарейсов (18 процентов от общего количества).
Вышедшая из строя система планирования и балансировки аэроданных используется для равномерного распределения веса внутри самолетов. Это особенно важно для авиакомпаний, выполняющих региональные рейсы на короткие расстояния. Компания AeroData еще в 1990 году выиграла тендер на предоставление соответствующих услуг, проведенный властями США.
Поскольку у Aerodata есть дата-центры в Аризоне и Колорадо. Неясно, где именно произошел сбой. Есть опасения, что инцидент мог быть вызван хакерами. Примечательно, что несколькими неделями ранее проблемы аналогичного плана возникли с системой продажи и бронирования билетов Sabre Corp, используемой рядом авиакомпаний. Это вызвало серию задержек в аэропортах США.
Даунтайм в дата-центре Sabre Corp обернулся головной болью для авиапассажиров
Упомянутый выше сбой в системе продажи и бронирования авиабилетов Sabre Corp случился 29 марта 2019 года и также привел к появлению длинных очередей из путешественников в американских аэропортах.
Причина сбоя в системе Sabre Corp неизвестна, но, как отмечают эксперты, большинство отключений начинаются с малого. Вероятно, в ЦОД компании произошло какое-то небольшое событие-триггер, которое инициировало крупный даунтайм.
В своем мартовском отчете для инвесторов в прошлом году Sabre Corp сообщала, что переносит рабочие нагрузки с мэйнфреймов IBM на серверы Intel. Компания планирует завершить миграцию к 2023 году.
Клиенты Wells Fargo столкнулись с задержками из-за задымления в ЦОД банка
Задымление в центре обработки данных вызывало перебои в работе клиентов банка Wells Fargo. Инцидент произошел 7 февраля 2019 года. Клиенты Wells Fargo столкнулись с проблемами при получении доступа к онлайн-банкингу и мобильному банкингу, а также к другим банковским услугам, включая получение наличных денег через банкоматы.
Инженеры обнаружили проблему после планового технического обслуживания. Инцидент произошел в дата-центре в городе Шорвью, штат Миннесота (США), около 5 часов утра по местному времени. Ситуацию удалось взять под контроль в 9 часов утра того же дня. В пресс-службе Wells Fargo отказались комментировать информацию о возможном источнике дыма. Неизвестно также, сколько клиентов Wells Fargo были затронуты инцидентом.
Больница в Орегоне частично приостановила работу из-за перебоев в электроснабжении местного дата-центра
Еще одна авария в ЦОД на территории американского штата Орегон заставила хирургов одной из местных больниц отложить сложные операции. Причиной инцидента, который произошел 7 февраля, стало отключение подачи электричества из центральной сети в дата-центр компании OneNeck с уровнем надежности Tier III. ЦОД расположен в городе Бенд.
Инцидент длился 45 минут и был успешно устранен. Из-за даунтайма в ЦОД, который обслуживает объекты местного поставщика услуг в области здравоохранения St Charles Health System, было решено отложить плановые операции.
Представители OneNeck не предоставили подробной информации о причине сбоя, но известно, что соответствующий ЦОД компании сертифицирован на соответствие требованиям Tier III и LEED. При этом там имеется маховиковая система ИБП, а также пассивная система фрикулинга и система охлаждения типа «киотское колесо» (ротационный теплообменник). Там также есть два генератора мощностью по 1,2 МВт.
Service Express предлагает мощный инструмент для профилактики аварий в ЦОД
Техническая компания Service Express запустила систему для ускорения поиска новых расходных материалов и запчастей для дата-центров OnDeck, в основе которой лежит запатентованная система предиктивной аналитики и технология машинного обучения. Продукт позиционируется как идеальное решение для профилактического обслуживания ЦОД.
С помощью алгоритмов прогнозирования OnDeck Service Express определяет и бронирует запасные части, необходимые для ремонта ЦОД, что приводит к более быстрой реакции на сбои в центрах обработки данных и увеличению времени безотказной работы серверных ферм.
Система OnDeck способна идентифицировать тенденции спроса на продукты для ЦОД по данным за десять лет. Она реагирует на потребности в таких продуктах, формируя новые заказы или корректируя локальный инвентарь, чтобы у операторов ЦОД появился критически важный продукт, прежде чем он действительно понадобится. Система работает в режиме 24/7/365 и поддерживает заказы компонентов для серверов, систем хранения данных и сетевых систем таких производителей как HPE, IBM, Dell EMC и так далее.

Всего комментариев: 0